When it comes to temporarily storing the data, Kubernetes provides few options for ephemeral volumes. These options include storing data on the host node (disk, memory) and using ephemeral local volumes.
When applications need to work with data that can be discarded after processing and does not need persistent storage, these ephemeral volumes come in handy.
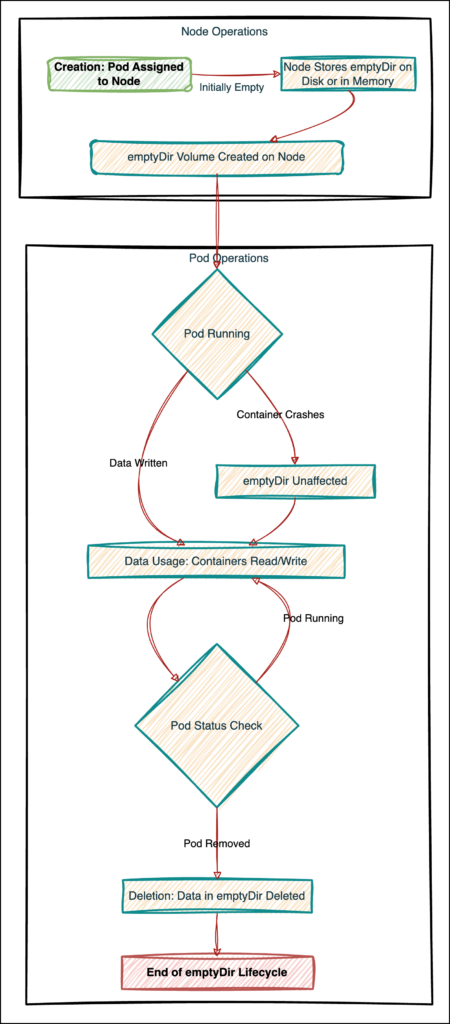
emptyDir is one such volume option that is easiest to work with. emptyDirvolume is created when a pod is assigned to a node and is deleted when the pod is removed.
Think
emptyDiras a scratchpad memory for Pods.
Unlike persistent volumes that outlive pod lifecycles, emptyDir exists solely for its pod’s lifespan, making it perfect for temporary data storage and sharing between containers within the same pod.
This post will explore the emptyDir theory, its lifecycle, and practical use cases for the effective use ofemptyDirin your clusters.
Table of Contents
Key Details about emptyDir
Lifecycle of emptyDir
Node Operations
- A pod is assigned to a node, triggering the creation of an
emptyDirvolume. This volume is initially empty and ready for use by the pod’s containers. - Depending on the configuration, the node stores the
emptyDirvolume on disk or in memory (if specified as a tmpfs).
Pod Operations
Creation
- The
emptyDirvolume is created on the node as soon as the pod is scheduled to run on that node. - This volume is accessible to all containers within the pod, providing a shared space for data storage and exchange.
Usage:
- Containers within the pod can read from and write to the
emptyDirvolume, using it to store data needed during the pod’s lifecycle temporarily. - The volume supports simultaneous access from multiple containers, allowing efficient data sharing and communication.
- If a container crashes, the data in
emptyDirremains unaffected, ensuring data persistence across the container restarts within the pod’s lifecycle. - Containers can mount the
emptyDirvolume at the same or different paths, offering flexibility in how the shared storage is used.
Deletion:
- Once the pod is removed from the node for any reason (e.g., pod deletion, node drain), the
emptyDirvolume, and all its data are deleted. - This deletion ensures that temporary data stored in the
emptyDirvolume does not persist beyond the lifecycle of the pod.
Practical use cases of emptyDir
1. Log Aggregation and Processing
Scenario: An application generates logs that must be aggregated, processed, or monitored in real time. An emptyDir volume can act as a centralized log directory where an application within the pod writes its logs. A separate container within the same pod can then process these logs, perform real-time analysis, or forward them to a centralized logging service.
This was one of the use cases I recently had to implement within my organization. We had an open-source application that created multiple log files based on the type of the log message. The Dev team needed all these logs in our central log store for analysis/ debugging.
Below is the high-level solution we implemented.
apiVersion: apps/v1
kind: Deployment
metadata:
name: log-aggregator
spec:
replicas: 1
selector:
matchLabels:
app: log-aggregator
template:
metadata:
labels:
app: log-aggregator
spec:
containers:
- name: web-server
image: nginx:alpine
volumeMounts:
- name: log-volume
mountPath: /var/log/nginx
- name: proxy-log-reader
image: busybox:1.36
args: [/bin/sh, -c, "tail -n+1 -F /var/log/access.log"]
volumeMounts:
- name: log-volume
mountPath: /var/log
volumes:
- name: log-volume
emptyDir: {}In summary, this deployment sets up a simple log aggregation system where Nginx serves as the web server generating logs, and BusyBox acts as a log reader, processing or monitoring the logs in real-time.
- The above example tails the Nginx access logs, which are not sent to
stdoutby default. - By tailing the logs on the
proxy-log-readercontainer asstdout, these logs are easily picked by a log collector like FluentD. - log-volume: An
emptyDirThe volume shared between the Nginx and BusyBox containers facilitates log aggregation and processing.
As we have learned above, the emptyDir location is /var/lib/kubelet/pods/{podid}/volumes/kubernetes.io~empty-dir/ on the host node. We can verify this using the below commands.
# get the pod UID
> POD=$(kubectl get po -l app=log-aggregator -o jsonpath="{.items[0].metadata.uid}")
# cd into the emptyDir path
> cd /var/lib/kubelet/pods/${POD}/volumes/
# get the directory details
> ls -l
total 8
drwxr-xr-x 3 root root 4096 Feb 15 11:49 kubernetes.io~empty-dir
drwxr-xr-x 3 root root 4096 Feb 15 11:49 kubernetes.io~projected
# once you cd into kubernetes.io~empty-dir, you should see a folder named as
# log-volume, this is volume name we have given above.
# this should have Nginx log files.
> cd kubernetes.io~empty-dir
> ls -l
total 4
drwxrwxrwx 2 root root 4096 Feb 15 11:49 log-volume
> cd log-volume
> ls -l
total 8
-rw-r--r-- 1 root root 249 Feb 15 11:50 access.log
-rw-r--r-- 1 root root 635 Feb 15 11:49 error.log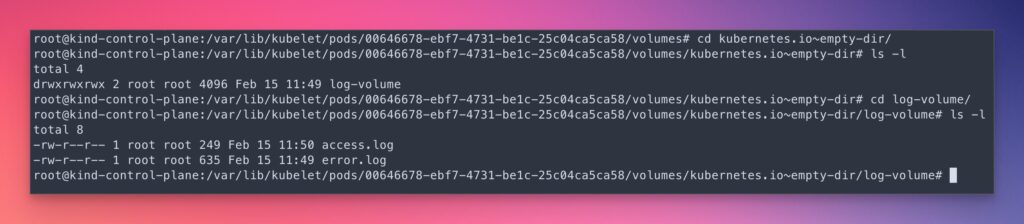
2. In-Memory Data Processing
Scenario: High-performance computing (HPC) applications or real-time data processing systems often require rapid access to temporary storage for processing data in memory, minimizing latency and maximizing throughput.
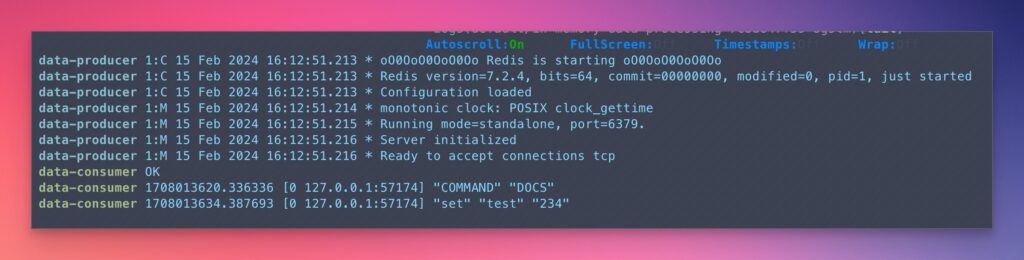
The below deployment uses Redis containers, one as a data producer to generate and store data in memory and another as a data consumer to process or monitor the data, both utilizing an emptyDir volume configured in RAM for fast data access.
apiVersion: apps/v1
kind: Deployment
metadata:
name: in-memory-data-processing
spec:
replicas: 1
selector:
matchLabels:
app: in-memory-data-processing
template:
metadata:
labels:
app: in-memory-data-processing
spec:
containers:
- name: data-producer
image: redis:alpine
command: ["redis-server", "--save", ""]
volumeMounts:
- name: data-volume
mountPath: /data
- name: data-consumer
image: redis:alpine
command: ["redis-cli", "monitor"]
volumeMounts:
- name: data-volume
mountPath: /data
volumes:
- name: data-volume
emptyDir:
medium: MemoryIn the above deployment, both the data-producer and data-consumercontainers mount the emptyDir volume set to use medium: Memory. This setup could be used in scenarios where the data-producer generates data that needs to be quickly accessed or processed by the data-consumer, benefiting from the high-speed, temporary storage provided by RAM.
3. Batch Job Processing
Scenario: Batch processing jobs that require a staging area for intermediate results or files before they are processed in the next stage of the workflow. emptyDir volumes offer a transient storage area where these files can be stored temporarily between processing steps, facilitating smooth and efficient data flow through the batch job pipeline.
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job-processing
spec:
template:
spec:
containers:
- name: job-worker
image: ubuntu:latest
command: ["/bin/sh", "-c"]
args: ["echo 'Processing batch job...' && sleep 60 && echo 'Job completed!'"]
volumeMounts:
- name: temp-storage
mountPath: /tmp/job-data
restartPolicy: Never
volumes:
- name: temp-storage
emptyDir:
sizeLimit: 500Mi
medium: MemoryThis deployment defines a Job named batch-job-processing designed to execute a batch processing task. The logic behind this configuration focuses on running a temporary, one-off task within a Kubernetes cluster, utilizing in-memory storage for intermediate data handling.
Note the use of emptyDir with a sizeLimit of 500Mi and medium: Memoryindicating the storage is in-memory (RAM) and capped at 500 MiB, optimizing performance for tasks requiring quick access to stored data and ensuring that the job’s data usage is within reasonable limits.
Conclusion
In conclusion, By offering a scratchpad memory for pods,emptyDir volume provides a key feature in Kubernetes for a simple yet effective solution for managing temporary data.
By following hands-on examples, you should have a solid understanding of how emptyDir works and a fair idea about the implementation for emptyDirin your use cases.
You can learn more about emptyDir on the official K8S documentation.
- https://kubernetes.io/docs/concepts/storage/volumes/#emptydir
- https://kubernetes-csi.github.io/docs/ephemeral-local-volumes.html
🙏 Thanks for your time and attention all the way through!
Till we meet again, keep making waves.🌊 🚀
Great article. I’d like to point that it seems to indicate that the emptyDir data is ONLY removed when the Pod is deleted from the node, but that is not the case. The emptyDir data is ALSO removed when a Pod enters a Succeeded or Failed state. For example, when all containers in Pod terminate and the the Pod’s restartPolicy is not Always (i.e. a typical Job Pod). Even though the Pod object still exists, the emptyDir contents are deleted from the node.